Intel's New AVX10 Brings AVX-512 Capabilities to E-Cores

Intel posted its new APX (Advanced Performance Extensions) today and also disclosed the new AVX10 [PDF] that will bring unified support for AVX-512 capabilities to both P-Cores and E-Cores for the first time. This evolution of the AVX instruction set will help Intel sidestep the severe issues it encountered with its new x86 hybrid architecture found in the Alder and Raptor Lake processors.
However, the new AVX10 ISA won't be supported with Intel's current-gen CPUs — it's slated to arrive in future chips. Intel says that AVX10 will be its vector ISA of choice moving into the future for both consumer and server processors.
Intel AVX10 (Advanced Instruction Extensions 10)
At its most basic level, AVX10 will allow Intel's chips that have both E-cores and P-cores to still support AVX-512, though 512-bit instructions can only run on P-cores. Meanwhile, converged 256-bit AVX10 instructions can run on either the p-cores or e-cores, thus allowing the full chip to still have support for AVX-512 capabilities.
As such, Intel won't have to disable support for 512-bit vectors as it did when it disabled AVX-512 for both Alder Lake and Raptor Lake.

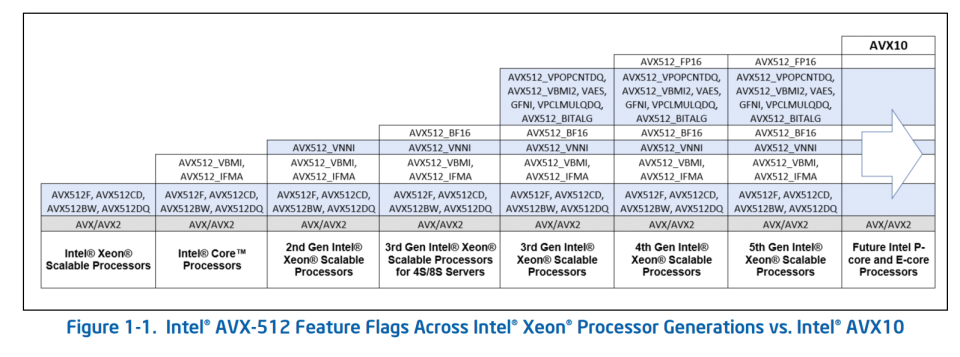
Diving deeper, the AVX10 (Advanced Instruction Extensions 10) ISA is a superset of AVX-512 and comes with all of the features of the AVX-512 ISA for processors with both 256-bit and 512-bit vector register sizes.
The converged AVX10 ISA will include "AVX-512 vector instructions with an AVX512VL feature flag, a maximum vector register length of 256 bits, as well as eight 32-bit mask registers and new versions of 256-bit instructions supporting embedded rounding," and this version will run on both p-cores and e-cores.
However, the e-cores will be limited to the converged AVX10's maximum 256-bit vector length, while P-cores can use 512-bit vectors. This feels akin to Arm's support for variable vector widths with SVE.
Intel says that existing applications will provide the same level of performance with AVX10 as they did with AVX-512, at least at the same vector lengths. Intel also claims:
Intel AVX2-compiled applications, re-compiled to Intel AVX10, should realize performance gains without the need for additional software tuning.
Intel AVX2 applications sensitive to vector register pressure will gain the most performance due to the 16 additional vector registers and new instructions.
Highly-threaded vectorizable applications are likely to achieve higher aggregate throughput when running on E-core-based Intel Xeon processors or on Intel products with performance hybrid architecture.
Intel will support AVX10 version 1 (AVX10.1) beginning with its sixth-gen Xeon "Granite Rapids" chips, but that generation will only support 512-bit vector instructions, and not the new converged 256-bit vector instructions. Instead, this first gen will serve as the transition chip from AVX-512 to AVX10.
Chips arriving after Granite Rapids will support AVX10.2, which adds support for the converged 256-bit vector lengths and other new features, like new AI data types and conversions, data movement optimizations, and standards support. All future Xeon processors will continue fully supporting all AVX-512 instructions to ensure that legacy apps function normally.
To address developer feedback (obviously negative), Intel also plans to significantly simplify its AVX10 enumeration methods compared to AVX-512. Intel also plans to ensure that each move to a new AVX10 revision has enough new instructions and capabilities to merit a change, thus reducing version and enumeration bloat.
Intel will freeze the AVX-512 ISA when AVX10 debuts, and all future use of AVX-512 instructions will occur through the AVX10 ISA. Meanwhile, the new AMX will be unimpacted.
Intel APX (Advanced Performance Extensions)
Intel also announced the new APX (Advanced Performance Extensions) today (not to be confused with the old-school iAPX 432).
Intel claims APX-compiled code contains 10% fewer loads and 20% fewer stores than the same code compiled for an Intel 64 baseline. Intel also says that register accesses are both faster and consume significantly less dynamic power than complex load and store operations. Interestingly, the new APX finds a new use for the 128B area that was left unused when Intel abandoned MPX back in 2019, and repurposes it for XSAVE.
Here are APX's top-level features:
16 additional general-purpose registers (GPRs) R16–R31, also referred to as Extended GPRs (EGPRs) in this document
Three-operand instruction formats with a new data destination (NDD) register for many integer instructions
Conditional ISA improvements: New conditional load, store and compare instructions, combined with an option for the compiler to suppress the status flags writes of common instructions
Optimized register state save/restore operations
A new 64-bit absolute direct jump instruction
Intel claims it has implemented APX in such a way that it will not impact the silicon area or power consumption of the CPU core. You can read much more about APX here, and Intel has a list of resources for both APX and AVX10 at the bottom of the linked page.
APX and AVX10 come on the heels of Intel's recent announcement that it is investigating slimming down the Intel 64 architecture to a simplified version of x86 named x86S.

